神農TAIDE
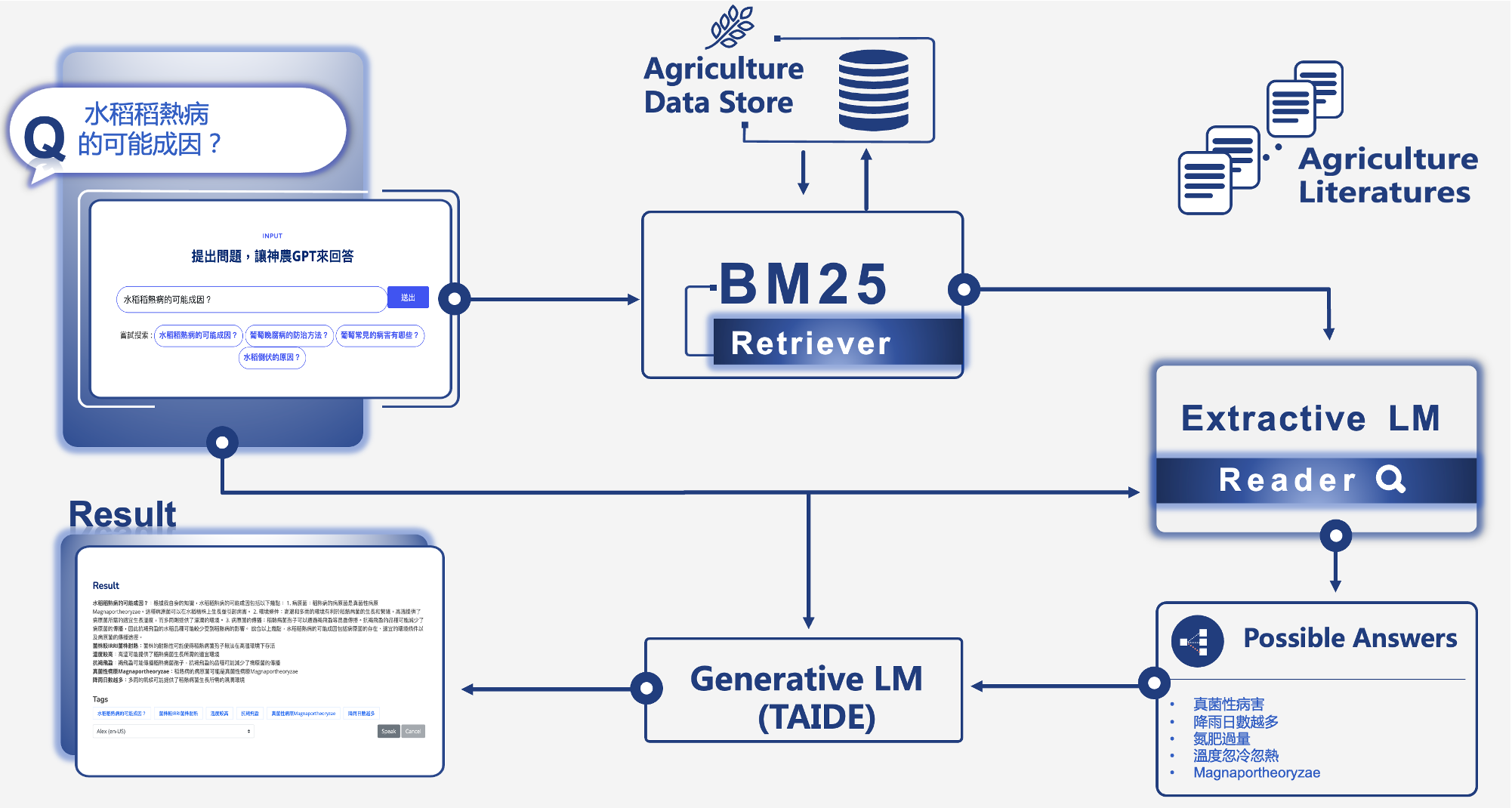
神農TAIDE為一個整合中興大學開發的文件檢索模型(Neural Dense Retriever)、萃取式閱讀模型(Extractive Reading Model)與TAIDE來實現Fact-Retrival的知識問答系統。
神農TAIDE確保回答的準確性和可信度。首先,我們使用檢索模型將使用者提出的問題與知識庫中的文獻檢索,並提供給萃取式閱讀模型提取出與問題答案相關的片段。
神農TAIDE優勢在於它只會回答知識庫中所包含的資料,因此可以確保回答的正確性。最後,我們將萃取式閱讀模型的結果傳遞給TAIDE,以進一步過濾和摘要這些答案,並進行簡潔的摘要說明。這樣的系統結合了檢索模型、萃取式閱讀模型和TAIDE的優勢,能夠提供準確、全面且易於理解的答案。